
分布式设计-Redis集群-Mysql集群-Cloud
分布式系统的概念
分布式系统是建立在网络之上的软件系统,拥有软件特性,所以分布式系统具有高度内聚性,和透明性。是建设于网络之上的高层软件,而不是硬件。
分布式系统特点
分布式系统是多个服务器通过网络互联而构建的松耦合系统,其具备以下特点:
- 分布式:分布式由多台计算机组成,在地域上是独立分散的,可以分散在一个单位,一个城市,一个国家,或是全球范围内。整个系统的统一功能是分散在多个节点上实现的,因而分布式系统具有数据处理的分布式特性。
- 自治性:分布式系统各个节点包含自己独有的cpu和内存,具备独立的处理数据能力。一般来说每个节点是对等的,没有主次之分,可以自治的进行任务处理,还可以通过网络传输信息,协同完成任务处理。
- 并行性:一个大的任务可以按规则划分到多个计算节点上进行独立的子任务支持,体现了并行性。
- 全局性:分布式系统必须存在一个单一的,全局的通信机制,使得任何一个进程都能和其他进程通信,并且不区分本地通信和远程通信。在一个分布式集群中,往往所有机器具有统一的系统调用能力。
在不同的抽象层次上来说,分布式系统中每一个物理机,虚拟机,docker镜像,独立进程都可以认为是一个节点。
特有缺点
- 由于网络不稳定因素存在,所以数据丢包,消息丢失时有发生,节点之间可能无法进行通信,也就是出现了所谓的网络分化,一般引入CAP进行系统分析。
- 网络传输同样会造成信息乱序问题,也就是网络传输过程中A节点发送给B节点的消息,在B节点接受消息时并不一定和A发送给B的顺序一样。这种情况可能造成业务上的问题,网络传输层次上我们可以了解下TCP的处理方式,业务上我们可以采用创建全局唯一发号器和业务幂等来处理乱序带来的如:消息的无效,信息的过期等业务问题。
- 分布式系统中,节点之间通信不像单机系统那样非成功即失败,我们考虑到网络不确定性带来的问题,所以分布式场景下存在“分布式三态”的概念。也就是说A节点调用B节点,可能是B节点返回成功,或是B节点返回失败,还有就是因为网络问题而产生的超时状态,针对这种问题我们一般采用“failfast”,“retry+幂等”等方式。
- 分布式网络中,通过负载均衡我们可以将请求将负载到不同节点进行数据处理,在进行数据查询时同样可能会负载到不同的节点进行数据获取。这个问题场景其实是值得深入讨论的,不同的业务要求,不同的业务容错场景存在不同的解决方案。我们可以从其他节点获取数据,也可以在数据保存时要求一定的数据一致性等级处理,在完成多节点数据复制,才响应客户端。
我们在进行分布式系统设计过程中需要面向异常进行系统架构设计,尽早在设计阶段考虑到可能遇到的异常问题,以进行容错的异常处理。
无状态服务体系下,请求可以被随机或是以哈希,一致性哈希等方式负载到不同到节点进行数据处理。节点异常可以随意的将问题节点下线和新节点扩容。但是对于有状态的分布式节点我们就不能简单的,随意的对分布式节点进行上下线操作了。
为解决分布式系统下有状态节点的数据完整性或叫做安全性的要求,我们一般采用多副本方式。
数据完整性
副本(replication)指的是在分布式系统中为数据节点或是数据单元进行的冗余。
对于数据和副本之间数据一致性上我们有以下几种实现方式:
- 强一致性:也就是说对于数据访问者而言,访问分布式网络下任意节点下的数据副本都可以读到最新更新的数据信息。实现强一致的数据复制会牺牲系统的并发能力和吞吐能力,实现方案上也较为复杂,业务上一般不采用这种方式。
- 单调一致性:意思是数据访问者一旦读取到某个数据副本最新的值,就不会在读到比这个副本值旧的值了。这个概念提出是为了满足以数据访问者视角来说的数据一致性。
- 会话一致性:数据访问者在一次会话之内一旦读取到最新数据副本之后就不会再读取到比这个数据旧的值了,听起来是不是和上面的很类似。区别在于这里要求的是一次会话,如果同一个数据访问者发起多次会话可能就不满足这个一致性要求了,其并不对多次会话一致性提供保障,所以它是弱与上面情况的一种一致性实现。
- 最终一致性:其要求一旦数据在某个副本更新成功,最终在各个副本上都可以访问到最终数据,以达到最终完全一致的状态,但是完整一致性的这个时间不做承诺。最终一致性一般是我们做分布式系统设计时采用的方案,而这个最终一致性的时间承诺来自于每个系统,中间件的SLA。
- 弱一致性:说的是数据更新成功之后,并不能在一个确定的时间内读到更新之后的值,也不承诺其他副本可以获取最新的值。所以弱一致性在真实场景中很难被系统所采纳。
分布式系统的副本机制很好的提升了分布式系统的高可用性,针对不同等级的一致性要求可以采用不同的解决方案,越是强一致性的模型对用户来说越友好,当然实现成本也更高。
考量指标
对于单机系统服务来说,我们考量系统的指标常来自于单机资源所带来的指标,比如内存,cpu,磁盘io等指标。分布式系统的性能指标则不一样:
- 系统吞吐能力,一般以系统每秒处理总数据量形容。
- 系统延迟能力,指的是完成一次任务处理所需要的时间。
- 系统并发能力,系统可以一起合作完成一项任务的能力,通常以QPS来衡量。
Redis集群
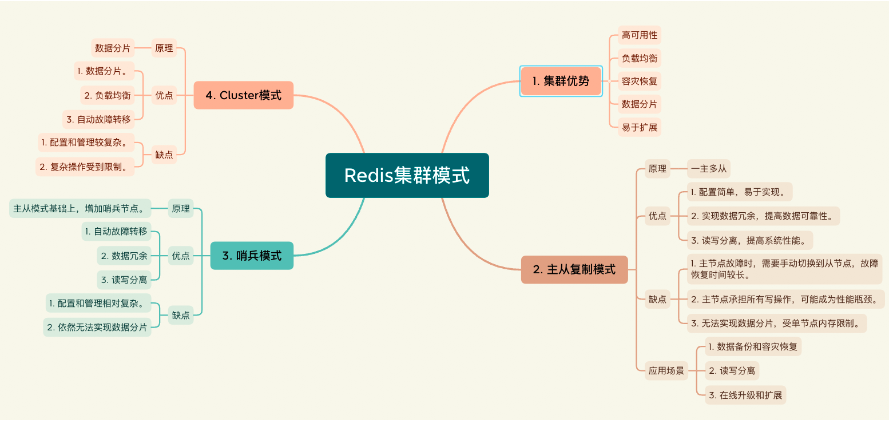
Redis集群简介
什么是Redis集群
Redis集群是一种通过将多个Redis节点连接在一起以实现高可用性、数据分片和负载均衡的技术。
它允许Redis在不同节点上同时提供服务,提高整体性能和可靠性。根据搭建的方式和集群的特性,Redis集群主要有三种模式:主从复制模式(Master-Slave)、哨兵模式(Sentinel)和Cluster模式。
Redis集群的作用和优势
- 高可用性:Redis集群可以在某个节点发生故障时,自动进行故障转移,保证服务的持续可用。
- 负载均衡:Redis集群可以将客户端请求分发到不同的节点上,有效地分摊节点的压力,提高系统的整体性能。
- 容灾恢复:通过主从复制或哨兵模式,Redis集群可以在主节点出现故障时,快速切换到从节点,实现业务的无缝切换。
- 数据分片:在Cluster模式下,Redis集群可以将数据分散在不同的节点上,从而突破单节点内存限制,实现更大规模的数据存储。
- 易于扩展:Redis集群可以根据业务需求和系统负载,动态地添加或移除节点,实现水平扩展。
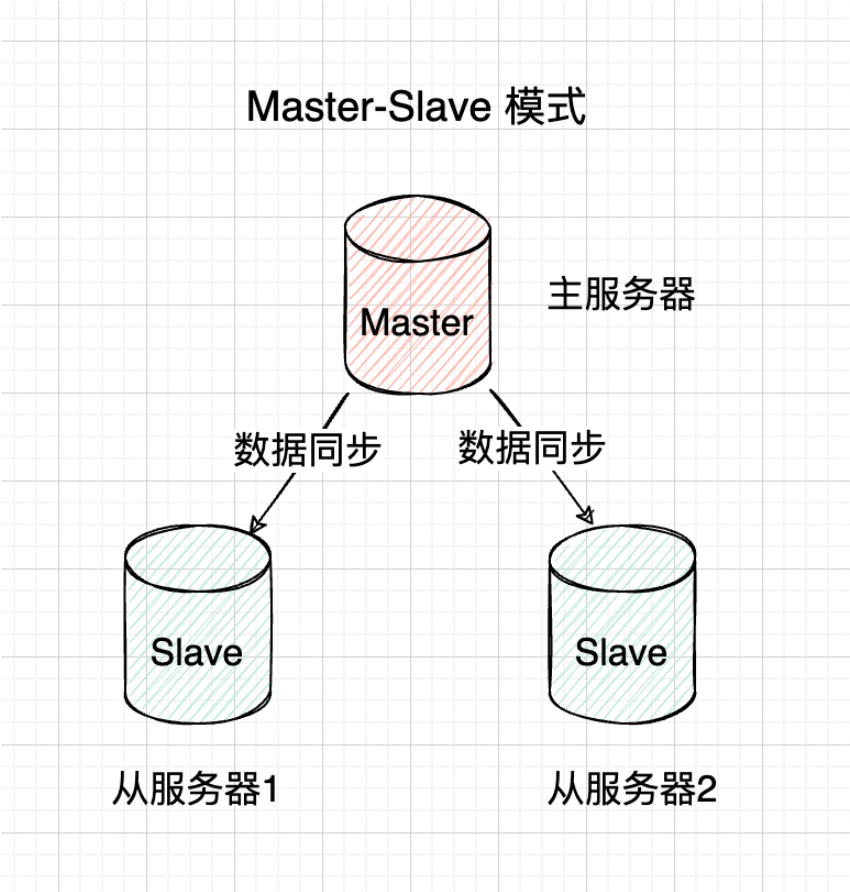
主从复制模式(Master-Slave)
主从复制原理
通过将一个Redis节点(主节点)的数据复制到一个或多个其他Redis节点(从节点)来实现数据的冗余和备份。
主节点负责处理客户端的写操作,同时从节点会实时同步主节点的数据。客户端可以从从节点读取数据,实现读写分离,提高系统性能。
主从复制配置和实现
配置主节点:在主节点的redis.conf配置文件中,无需进行特殊配置,主节点默认监听所有客户端请求。
# 主节点默认端口号6379
port 6379配置从节点:在从节点的redis.conf配置文件中,添加如下配置,指定主节点的地址和端口:
# 从节点设置端口号6380
port 6380
# replicaof 主节点IP 主节点端口
replicaof 127.0.0.1 6379或者,通过Redis命令行在从节点上执行如下命令:
redis> replicaof 127.0.0.1 6379
验证主从复制:在主节点上执行写操作,然后在从节点上进行读操作,检查数据是否一致。
主从复制的优缺点
优点:
- 配置简单,易于实现。
- 实现数据冗余,提高数据可靠性。
- 读写分离,提高系统性能。
缺点:
- 主节点故障时,需要手动切换到从节点,故障恢复时间较长。
- 主节点承担所有写操作,可能成为性能瓶颈。
- 无法实现数据分片,受单节点内存限制。
主从复制场景应用
- 数据备份和容灾恢复:通过从节点备份主节点的数据,实现数据冗余。
- 读写分离:将读操作分发到从节点,减轻主节点压力,提高系统性能。
- 在线升级和扩展:在不影响主节点的情况下,通过增加从节点来扩展系统的读取能力。
主从复制模式适合数据备份、读写分离和在线升级等场景,但在主节点故障时需要手动切换,不能自动实现故障转移。如果对高可用性要求较高,可以考虑使用哨兵模式或Cluster模式。
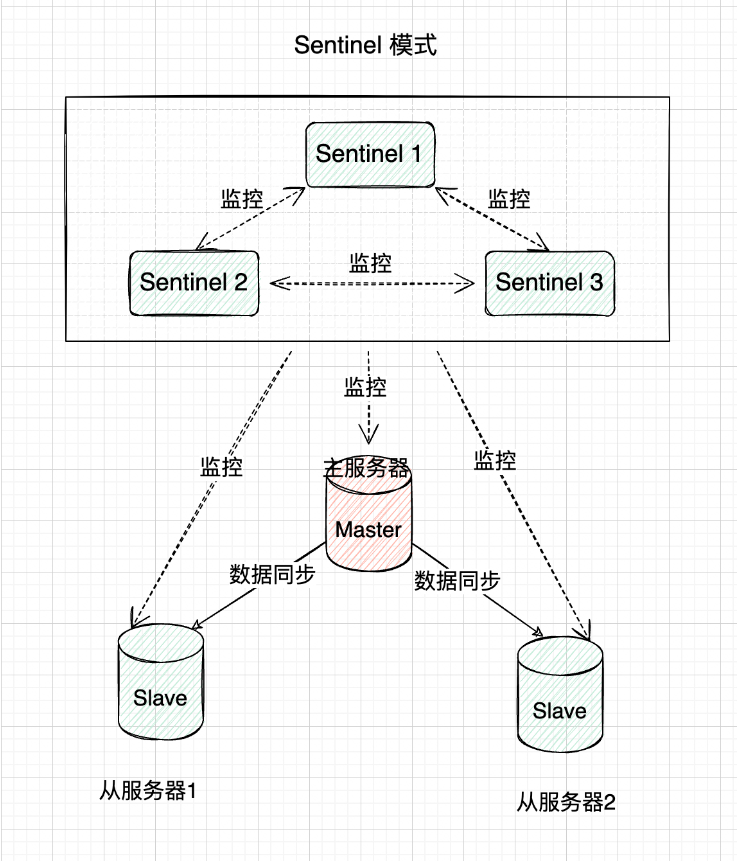
哨兵模式(Sentinel)
哨兵模式原理
哨兵模式是在主从复制基础上加入了哨兵节点,实现了自动故障转移。哨兵节点是一种特殊的Redis节点,它会监控主节点和从节点的运行状态。当主节点发生故障时,哨兵节点会自动从从节点中选举出一个新的主节点,并通知其他从节点和客户端,实现故障转移。
哨兵模式配置和实现
配置主从复制:首先按照主从复制模式的配置方法,搭建一个主从复制集群。
配置哨兵节点:在哨兵节点上创建一个新的哨兵配置文件(如:sentinel.conf),并添加如下配置:
# sentinel节点端口号
port 26379
# sentinel monitor 被监控主节点名称 主节点IP 主节点端口 quorum
sentinel monitor mymaster 127.0.0.1 6379 2
# sentinel down-after-milliseconds 被监控主节点名称 毫秒数
sentinel down-after-milliseconds mymaster 60000
# sentinel failover-timeout 被监控主节点名称 毫秒数
sentinel failover-timeout mymaster 180000其中,
quorum是指触发故障转移所需的最小哨兵节点数。down-after-milliseconds表示主节点被判断为失效的时间。failover-timeout是故障转移超时时间。为什么只配置了sentinel监控主节点,没有配置监控从节点?
因为通过主节点,就可以找到从节点。启动哨兵节点:使用如下命令启动哨兵节点:
redis> redis-sentinel /path/to/sentinel.conf
验证哨兵模式:手动停止主节点,观察哨兵节点是否自动选举出新的主节点,并通知其他从节点和客户端。
哨兵模式的优缺点
优点:
- 自动故障转移,提高系统的高可用性。
- 具有主从复制模式的所有优点,如数据冗余和读写分离。
缺点:
- 配置和管理相对复杂。
- 依然无法实现数据分片,受单节点内存限制。
哨兵模式场景应用
- 高可用性要求较高的场景:通过自动故障转移,确保服务的持续可用。
- 数据备份和容灾恢复:在主从复制的基础上,提供自动故障转移功能。
哨兵模式在主从复制模式的基础上实现了自动故障转移,提高了系统的高可用性。然而,它仍然无法实现数据分片。如果需要实现数据分片和负载均衡,可以考虑使用Cluster模式。
Cluster模式
Cluster模式原理
Cluster模式是Redis的一种高级集群模式,它通过数据分片和分布式存储实现了负载均衡和高可用性。在Cluster模式下,Redis将所有的键值对数据分散在多个节点上。每个节点负责一部分数据,称为槽位。通过对数据的分片,Cluster模式可以突破单节点的内存限制,实现更大规模的数据存储。
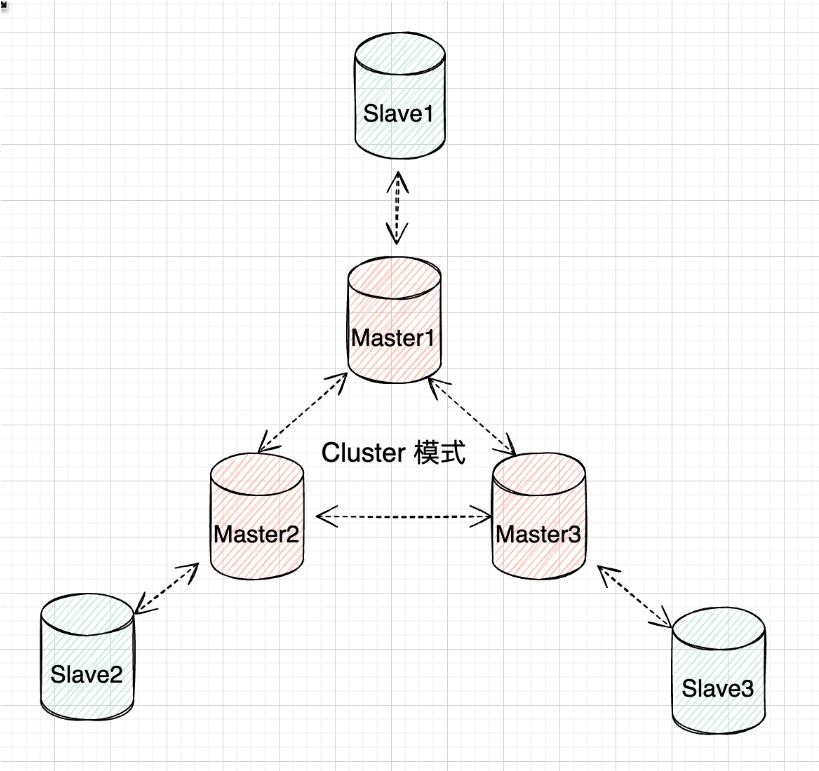
数据分片与槽位
Redis Cluster将数据分为16384个槽位,每个节点负责管理一部分槽位。当客户端向Redis Cluster发送请求时,Cluster会根据键的哈希值将请求路由到相应的节点。具体来说,Redis Cluster使用CRC16算法计算键的哈希值,然后对16384取模,得到槽位编号。
Cluster模式配置和实现
配置Redis节点:为每个节点创建一个redis.conf配置文件,并添加如下配置:
# cluster节点端口号
port 7001
# 开启集群模式
cluster-enabled yes
# 节点超时时间
cluster-node-timeout 15000
像这样的配置,一共需要创建6个,我们做一个三主三从的集群。
启动Redis节点:使用如下命令启动6个节点:
redis> redis-server redis_7001.conf
创建Redis Cluster:使用Redis命令行工具执行如下命令创建Cluster:
redis> redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
cluster-replicas 表示从节点的数量,1代表每个主节点都有一个从节点。
验证Cluster模式:向Cluster发送请求,观察请求是否正确路由到相应的节点。
Cluster模式的优缺点
优点:
- 数据分片,实现大规模数据存储。
- 负载均衡,提高系统性能。
- 自动故障转移,提高高可用性。【Redis】Redis Cluster-集群故障转移
缺点:
- 配置和管理较复杂。
- 一些复杂的多键操作可能受到限制。
Cluster模式场景应用
- 大规模数据存储:通过数据分片,突破单节点内存限制。
- 高性能要求场景:通过负载均衡,提高系统性能。
- 高可用性要求场景:通过自动故障转移,确保服务的持续可用。
Cluster模式在提供高可用性的同时,实现了数据分片和负载均衡,适用于大规模数据存储和高性能要求的场景。然而,它的配置和管理相对复杂,且某些复杂的多键操作可能受到限制。





