
WebMagic-入门
HttpClient
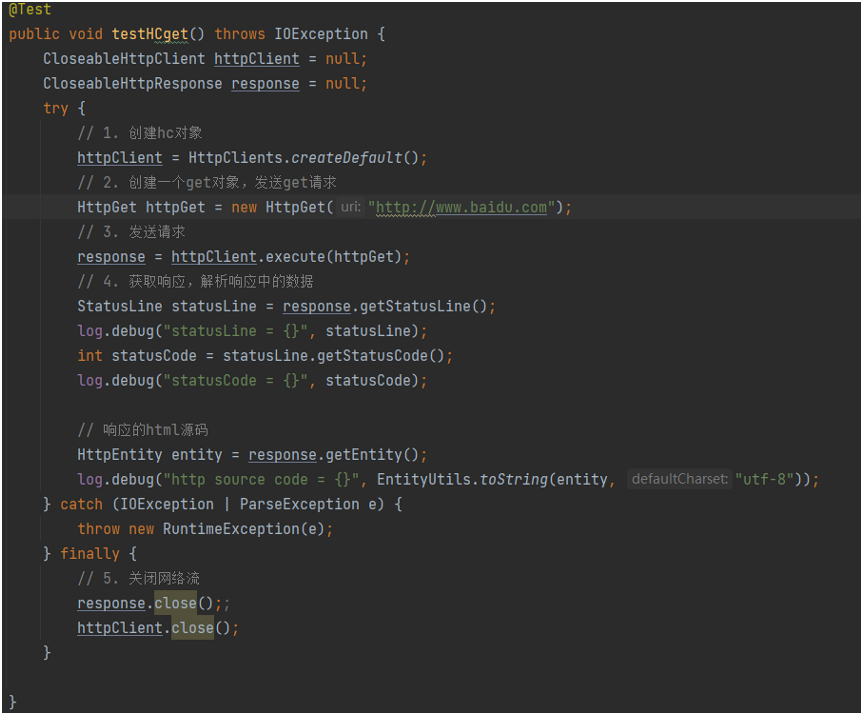
响应
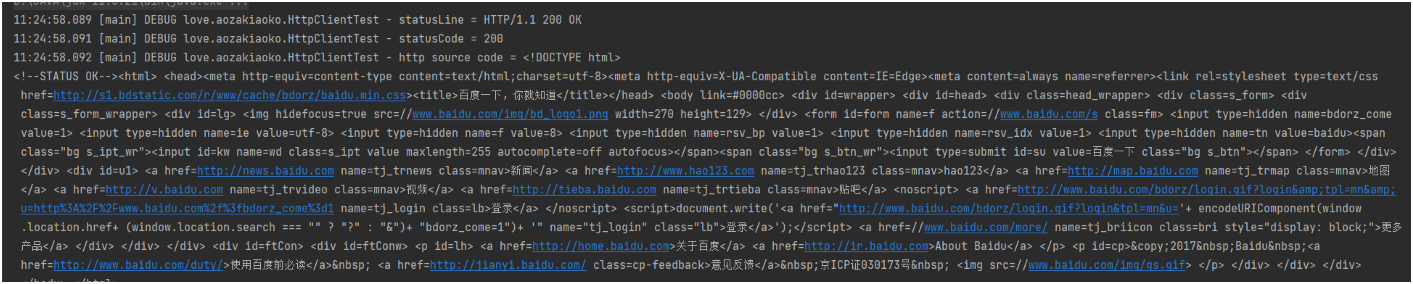
Post请求填充参数的方式
如下图的两种方式:
WebMagic概览
WebMagic 的设计参考了业界最优秀的爬虫 Scrapy,而实现则应用了 HttpClient、Jsoup 等 Java 世界最成熟的工具,目标是做一个 Java 语言 Web 爬虫的教科书般的实现。
WebMagic 总体架构可以分为四个部分,由 Spider 将它们组织起来:
- Downloader
- 负责从互联网上下载页面,以便后续的处理,WebMagic 默认使用了 Apache HttpClient 作为下载工具。
- PageProcessor
- 负责解析页面,抽取有用信息,发现新的连接。WebMagic 使用 Jsoup 作为 HTML 解析工具,并基于其开发了解析 XPath 的工具 Xsoup。
- 在这四个组件中,PageProcessor 对于每个站点每个页面都不一样,是需要使用者定制的部分。
- Scheduler
- 负责管理待抓取的 URL,以及一些去重的工作。默认提供 JDK 的内存队列来管理 URL,并使用集合来去重,也支持使用 Redis 进行分布式管理。
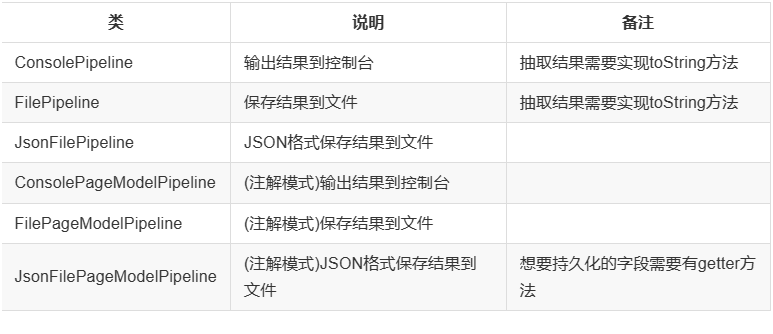
- Pipeline
- 负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic 默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
- Pipeline 定义了结果保存的方式,如果要保存到指定数据库,则需要编写对应的 Pipeline,对于一类需求一般只需要编写一个 Pipeline。
用于数据流转的对象:
- Request
- 对 URL 地址的一层封装,一个 Request 对应了一个 URL 地址。
- 它是 PageProcessor 与 Downloader 交互的载体,也是 PageProcessor 控制 Downloader 唯一方式。
- 除了 URL 本身以外,它还包含一个
extra额外字段,可以在 extra 中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息。
- Page
- Page 代表了从 Downloader 下载到的一个页面,可能是 HTML,也可能是 JSON 或者其他文本格式的内容。
- Page 是 WebMagic 抽取过程的核心对象,它提供一些方法可供抽取、结果保存等等。
- ResultItems
- ResultItems 相当于一个 Map,它保存 PageProcessor 处理的结果,供 Pipeline 使用。它的 API 与 Map 很类似,值得注意的是它有一个字段
skip,若设置为 true,则不被 Pipeline 处理。
- ResultItems 相当于一个 Map,它保存 PageProcessor 处理的结果,供 Pipeline 使用。它的 API 与 Map 很类似,值得注意的是它有一个字段
控制爬虫运转的引擎–Spider
- Spider 是 WebMagic 内部流程的核心。Downloader、PageProcessor、Scheduler、Pipeline 都是 Spider 的一个属性,这些属性是可以自由设置的,通过设置这个属性可以实现不同的功能。
- Spider 也是 WebMagic 操作的入口,它封装了爬虫的创建、启动、停止、多线程等功能。
- 案例:

WebMagic 项目组成
WebMagic 代码包括几个部分,在根目录下以不同目录名分开,它们都是独立的 Maven 项目。
- 主要部分
- webmagic-core
- webmagic-core 是 WebMagic 核心部分,只包含爬虫基本模块和基本抽取器。WebMagic-core 的目标是成为网页爬虫的一个教科书般的实现。
- webmagic-extension
- webmagic-extension 是 WebMagic 的主要扩展模块,提供一些更方便的编写爬虫的工具。包括注解格式定义爬虫、JSON、分布式等支持。
- webmagic-core
- 外围功能
- Webmagic-samples
- 这里是作者早期编写的一些爬虫的例子。因为时间有限,这些例子有些使用的仍然是老版本的 API,也可能有一些因为目标页面的结构变化不再可用了。最新的、精选过的例子,请看 webmagic-core 的
us.codecraft.webmagic.processor.example包和us.codecraft.webmagic.example包。
- 这里是作者早期编写的一些爬虫的例子。因为时间有限,这些例子有些使用的仍然是老版本的 API,也可能有一些因为目标页面的结构变化不再可用了。最新的、精选过的例子,请看 webmagic-core 的
- Webmagic-scripts
- WebMagic 对于爬虫规则脚本化的一些尝试,目标是让开发者脱离 Java 语言,来进行简单、快速的开发。同时强调脚本的共享。
- Webmagic-selenium
- WebMagic 与 Selenium 结合的模块。Selenium 是一个模拟浏览器进行页面渲染的工具,WebMagic 依赖 Selenium 进行动态页面的抓取。
- Webmagic-saxon
- WebMagic 与 Saxon 结合的模块。Saxon 是一个 XPath、XSLT 的解析工具,WebMagic 依赖 Saxon 来进行 XPath 2.0 语法解析支持。
- webmagic-avalon
- webmagic-avalon 是一个特殊的项目,它想基于 WebMagic 实现一个产品化的工具,涵盖爬虫的创建、爬虫的管理等后台工具。Avalon 是亚瑟王传说中的“理想之岛”,webmagic-avalon 的目标是提供一个通用的爬虫产品,达到这个目标绝非易事,所以取名也有一点“理想”的意味,但是作者一直在朝这个目标努力。
- Webmagic-samples
WebMagic快速开始
使用 Maven
添加以下依赖到你的 pom.xml 文件中:
<dependency> |
不使用 Maven
如果不使用 Maven,可以从 WebMagic 官网 下载最新的 JAR 包。我已将所有依赖的 JAR 包都打包在一起,点击 这里 下载。
下载后进行解压,然后在项目中导入即可。
导入 JARs
由于 WebMagic 提倡自定义,因此查看项目源码是有必要的。在 WebMagic 官网 上,你可以下载最新的 webmagic-core-{version}-sources.jar 和 webmagic-extension-{version}-sources.jar,并通过 “Attach Source” 进行源码关联。
编写基本的爬虫
实现 PageProcessor
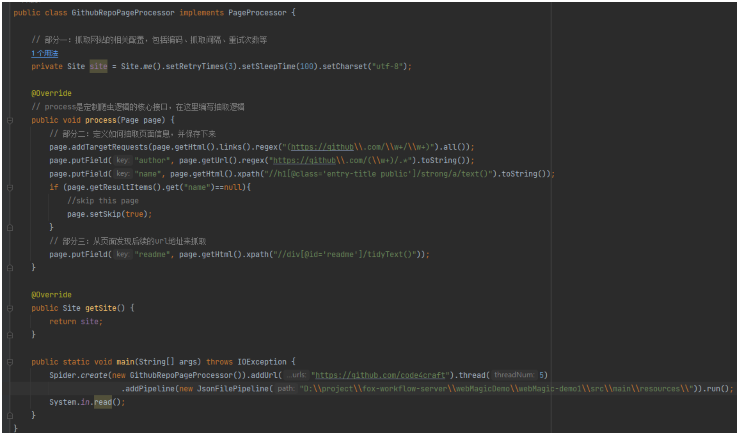
本部分通过 GithubRepoProcessor 进行说明:
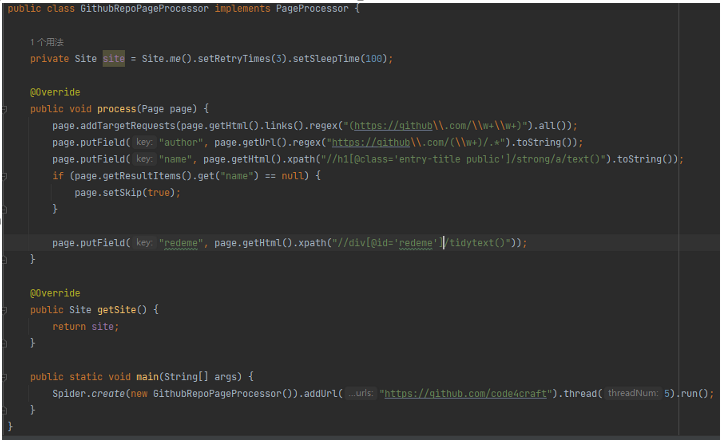
PageProcessor 的定制可以分为三个部分:
- 爬虫的配置
- 页面元素的抽取
- 链接的发现
出现 No appropriate protocol (protocol is disabled or cipher suites are inappropriate) 错误
解决方法 1
修改 JDK 目录 conf\security\java.security 中的 jdk.tls.disabledAlgorithms:
原始配置: |
如果没有作用,可以尝试下面的方法。
解决方法 2
复制源码中的
HttpClientGenerator和HttpClientDownloader到自己的项目中。修改
HttpClientGenerator的代码,只需要修改buildSSLConnectionSocketFactory这个方法为如下:private SSLConnectionSocketFactory buildSSLConnectionSocketFactory() {
try {
return new SSLConnectionSocketFactory(createIgnoreVerifySSL(), new String[]{"SSLv3", "TLSv1", "TLSv1.1", "TLSv1.2"},
null, new DefaultHostnameVerifier()); // 优先绕过安全证书
} catch (KeyManagementException e) {
logger.error("ssl connection fail", e);
} catch (NoSuchAlgorithmException e) {
logger.error("ssl connection fail", e);
}
return SSLConnectionSocketFactory.getSocketFactory();
}DefaultHostnameVerifier需要使用org.apache.http.conn.ssl.DefaultHostnameVerifier,而不要使用sun.net.www.protocol.https.DefaultHostnameVerifier。修改
HttpClientDownloader中引用的HttpClientGenerator为修改后的类。设置爬虫
Spider的Downloader为修改的HttpClientDownloader:Spider.create(new GithubRepoPageProcessor())
.setDownloader(new HttpClientDownloader())
.addUrl("https://github.com/code4craft")
.thread(5)
.run();
如果仍然不起作用,可以尝试更新版本。
解决方法 3
更新版本,问题解决。使用的版本:
<!-- https://mvnrepository.com/artifact/us.codecraft/webmagic-core --> |
爬虫的配置
- 主要在部分一,包括编码、抓取间隔、超时时间、重试次数等,也包括一些模拟的参数,例如 User Agent、cookie、以及代理的设置。
页面元素的抽取
对于下载到的 HTML 页面,WebMagic 里主要使用了三种抽取技术:XPath、正则表达式和 CSS 选择器。另外,对于 JSON 格式的内容,可以使用 JsonPath 进行解析。
Xpath:
page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()")
它的意思是查找所有
class属性为entry-title public的 h1 元素,并找到它的strong子节点的a子节点,并提取a节点的文本信息。CSS选择器:
- CSS选择器是与XPath类似的语言,它比XPath写起来要简单一些,但是如果写复杂一点的抽取规则,就相对要麻烦一点。
正则表达式:
- 一种通用的文本抽取语言。
JsonPath:
- 类似于XPath的一门语言,用于从Json中快速定位一条内容。
链接的发现
一个站点的页面是很多的,一开始我们不可能全部列举出来,因此如何发现后续的链接,是一个爬虫不可缺少的一部分。
page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all()); |
- 这段代码分为两部分,
page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all()用于获取所有满足"(https://github\\.com/\\w+/\\w+)"这个正则表达式的链接,page.addTargetRequests()则将这些链接加入到待抓取的队列中去。
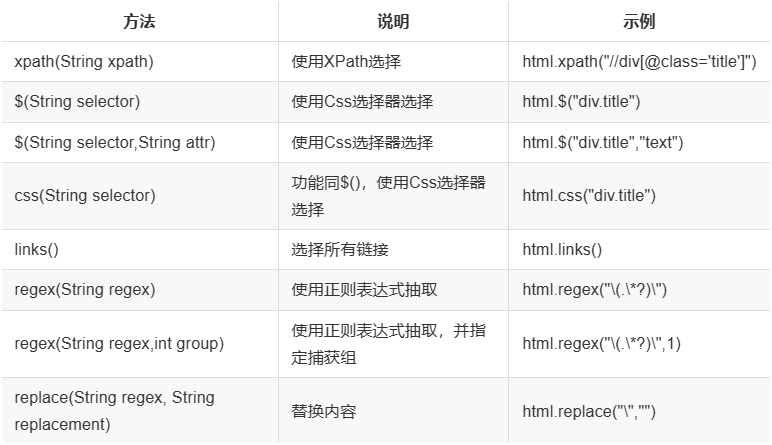
使用 Selectable 抽取元素
- Selectable 相关的抽取元素链式 API 是 WebMagic 的一个核心功能。使用 Selectable 接口,你可以直接完成页面元素的链式抽取,也无需去关心抽取的细节。
- 在刚才的例子中可以看到,
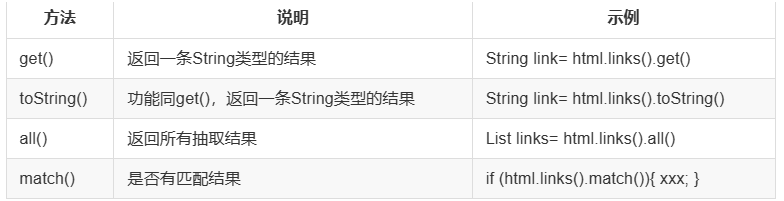
page.getHtml()返回的是一个Html对象,它实现了Selectable接口。这个接口包含一些重要的方法,可以分为两类:抽取部分和获取结果部分。
抽取部分 API
获取结果的 API
使用 Pipeline 保存结果
我们通过“控制台输出结果”这件事也是通过一个内置的 Pipeline 完成的,它叫做 ConsolePipeline。如果想要把结果用 Json 的格式保存下来,可以将 Pipeline 的实现换成 JsonFilePipeline:
public static void main(String[] args) { |
这样下载下来的文件就会保存在 D 盘的 webmagic 目录中。通过定制 Pipeline,我们还可以实现保存结果到文件、数据库等一系列功能。这个会在第7章“抽取结果的处理”中介绍。
爬虫的配置、启动和终止
Spider 是爬虫启动的入口。在启动爬虫之前,我们需要使用一个 PageProcessor 创建一个 Spider 对象,然后使用 run() 进行启动。同时 Spider 的其他组件(Downloader、Scheduler、Pipeline)都可以通过 set 方法来进行设置。
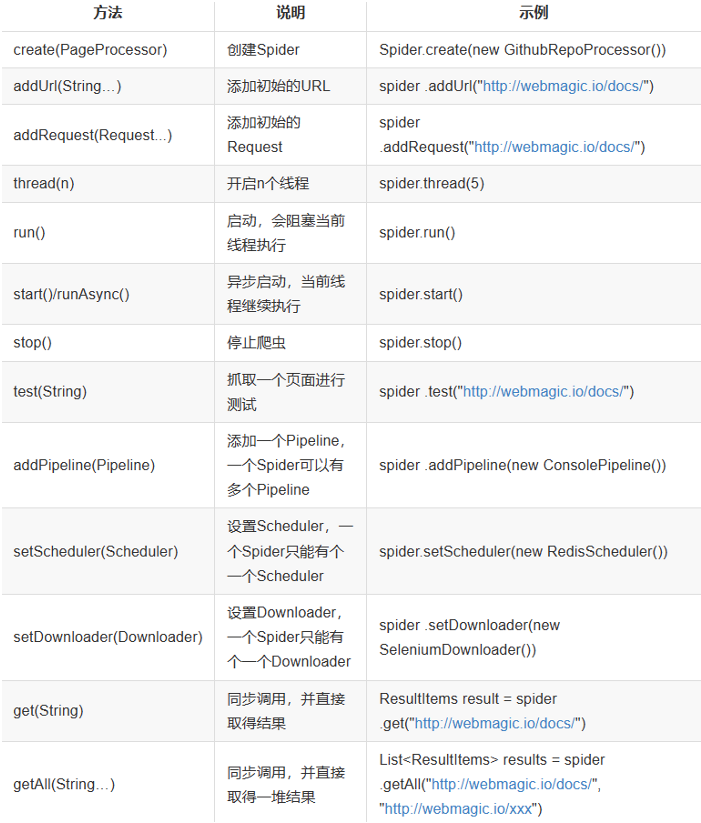
Site
对站点本身的一些配置信息,例如编码、HTTP 头、超时时间、重试策略等、代理等,都可以通过设置 Site 对象来进行配置。
Xsoup
- Xsoup 发展到现在,已经支持爬虫常用的语法,以下是一些已支持的语法对照表:
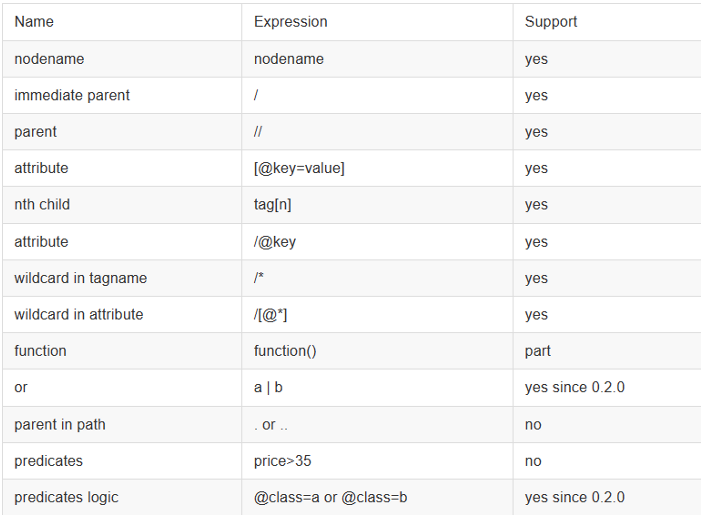
- 方便的 XPath 函数:

爬虫的监控
- 可以查看爬虫的执行情况–已经下载了多少页面、还有多少页面、启动了多少线程等信息。该功能通过 JMX 实现,可以使用 JConsole 等 JMX 工具查看本地或者远程的爬虫信息。
- 如果自定义了
Scheduler,需要使用这个类实现MonitorableScheduler接口,才能查看LeftPageCount和TotalPageCount。
为项目添加监控
获取一个 SpiderMonitor 的单例 SpiderMonitor.instance(),并将你想要监控的 Spider 注册进去即可,你可以注册多个 Spider 到 SpiderMonitor 中。
查看监控信息
WebMagic 的监控使用 JMX 提供支持,可以使用任何支持 JMX 的客户端进行连接。
扩展监控接口
可以通过继承 SpiderStatusMXBean 来实现扩展。
配置代理
从 0.7.1 版本开始,WebMagic 使用了新的代理 API ProxyProvider,新的代理 API 不再从 Site 设置,而是由 HttpClientDownloader 设置。

ProxyProvider有一个默认实现:SimpleProxyProvider。它是一个基于简单 Round-Robin 的、没有失败检查的ProxyProvider。可以配置任意个候选代理,每次会按顺序挑选一个代理使用。它适合用在自己搭建的比较稳定的代理的场景。

处理非 HTTP GET 请求
- 从 0.7.1 版本之后,废弃了老的
nameValuePair的写法,采用在Request对象上添加Method和requestBody来实现。

初始化方式

POST 的去重
从 0.7.1 版本开始,POST 默认不会去重,如果想要去重可以自己继承 DuplicateRemovedScheduler,重写 push 方法。
使用注解编写爬虫
入门案例
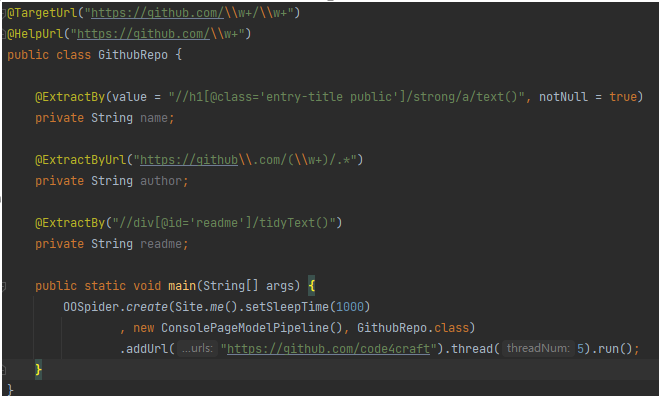
编写 Model 类
TargetUrl 与 HelpUrl
HelpUrl/TargetUrl 是一个非常有效的爬虫开发模式,TargetUrl 是我们最终要抓取的 URL,最终想要的数据都来自这里;而 HelpUrl 则是为了发现这个最终 URL,我们需要访问的页面,几乎所有垂直爬虫的需求,都可以归结为对这两类 URL 的处理:
- 对于博客页:HelpUrl 是列表页,TargetUrl 是文章页。
- 对于论坛:HelpUrl 是帖子列表,TargetUrl 是帖子详情。
- 对于电商网站:HelpUrl 是分类列表,TargetUrl 是商品详细页。
TargetUrl 的自定义正则表达式:
- 将 URL 常用的字符
.默认做了转义,变成了\.。 - 将
*替换成了.*,直接使用可表示通配符。
- 将 URL 常用的字符
在 WebMagic 中,从 TargetUrl 页面得到的 URL,只要符合 TargetUrl 的格式,也是会被下载的,所以即使不指定 HelpUrl 也是可以的–例如某些博客页总会有“下一篇”链接,这种情况下无需指定 HelpUrl。
sourceRegion:
- TargetUrl 还支持定义
sourceRegion,这个参数是一个 XPath 表达式,指定了这个 URL 从哪里得到–不在sourceRegion的 URL 不会被抽取。
- TargetUrl 还支持定义
使用 @ExtractBy 进行抽取
@ExtractBy是一个用于抽取元素的注解,它描述了一种抽取规则。@ExtractBy注解主要作用于字段,它表示“使用这个抽取规则,将抽取到的结果保存到这个字段中”。抽取方式
- XPath
- CSS 选择器
- 正则表达式
- JsonPath
使用方式
value属性是具体抽取的规则。type属性是使用的规则类型,有对应的枚举ExtractBy.Type.Css。notNull属性:true/false,如果为 true,则字段为空的结果会被丢弃,默认为 false。
@ExtractByUrl
@ExtractByUrl是一个单独的注解,它的意思是“从 URL 中进行抽取”。它只支持正则表达式作为抽取规则。
在类上使用 @ExtractBy
- 在之前的注解模式中,我们一个页面只对应一条结果,如果一个页面由多个抽取的记录呢?在类上使用
@ExtractBy注解可以解决这个问题,意思是使用这个结果抽取一个区域,让这块区域对应一个结果。 - 对应的,在这个类中的字段上再使用
@ExtractBy的话,则是从这个区域而不是整个页面进行抽取。如果这个时候仍想要从整个页面抽取,则可以设置source = RawHtml。
- 在之前的注解模式中,我们一个页面只对应一条结果,如果一个页面由多个抽取的记录呢?在类上使用
结果的类型转换
Formatter 机制 是 WebMagic 0.3.2 增加的功能。因为抽取到的内容总是 String,而我们想要的内容可能是其他类型。Formatter 可以将抽取到的内容,自动转换成一些基本类型,而无需手动使用代码进行转换。
自动转换 支持所有基本类型和装箱类型。
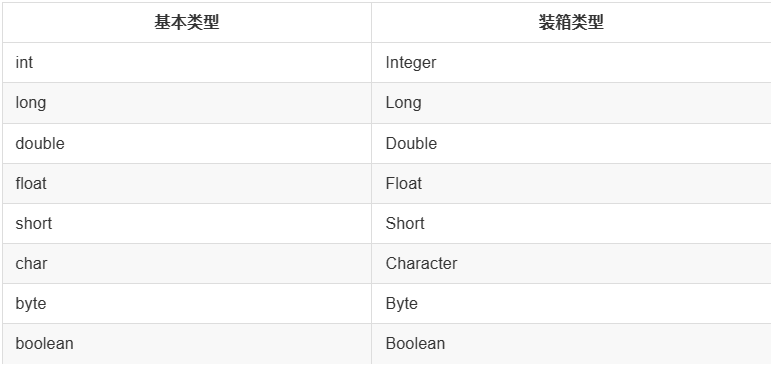
另外,还支持
java.util.Date类型的转换,但是在转换时,需要指定 Date 的格式。格式按照 JDK 的标准来定义,具体规范见 SimpleDateFormat。
显式指定转换类型
一般情况下,Formatter 会根据字段类型进行转换,但是特殊情况下,我们会需要手动指定类型。这主要发生在字段是 List 类型的时候。
自定义 Formatter
除了自动类型转换之外,Formatter 还可以做一些结果的后处理,例如,有一种需求场景,需要将抽取的结果作为结果的一部分,拼接上一部分字符串来使用。

完整的流程
爬虫的创建和启动
- 注解模式的入口是
OOSpider,它继承了Spider类,提供了特殊的创建方法,其他的方法是类似的。创建一个注解模式的爬虫需要一个或者多个 Model 类,以及一个或者多个PageModelPipeline–定义处理结果的方式。
- 注解模式的入口是
PageModelPipeline
注解模式下,处理结果的类叫做
PageModelPipeline,通过实现它,你可以自定义自己的结果处理方式。PageModelPipeline与 Model 类是对应的,多个 Model 可以对应一个PageModelPipeline。
AfterExtractor
有时候,注解模式无法满足所有需求,我们可能还需要写代码完成一些事情,这个时候就要用到
AfterExtractor接口。让 Model 实现AfterExtractor接口。afterProcess方法会在抽取结束,字段都初始化完毕之后被调用,可以处理一些特殊的逻辑。
组件的使用和定制
除了 PageProcessor 在 Spider 创建的时候已经指定,Downloader、Scheduler 和 Pipeline 都可以通过 Spider 的 setter 方法来进行配置和更改。
使用和定制 Pipeline
Pipeline是抽取结束后,进行处理的部分,它主要用于抽取结果的保存,也可以定制Pipeline来实现一些通用的功能。
本质上,
Pipeline就是将PageProcessor抽取的结果,进行进一步的处理,在Pipeline中完成的功能,其实也可以直接在PageProcessor中实现,但仍然需要Pipeline的原因如下:- 为了模块分类,“页面抽取”和“后处理、持久化”是爬虫的两个阶段,将其分离开来,一个是代码结构比较清晰,另一个是以后也可能将其处理过程分开,分开在独立的线程以至于不同的机器执行。
Pipeline的功能比较固定、保存到数据库这种操作,对于所有的页面都是通用的。WebMagic 中就已经提供了控制台输出、保存到文件、保存为 JSON 格式的文件几种通用的Pipeline。- 在 WebMagic 里,一个
Spider可以有多个Pipeline,使用Spider.addPipeline()即可增加一个Pipeline。这些Pipeline都会得到处理。

实现输出结果到控制台,并且保存到文件的目标:

将结果保存到 MySQL:
- 需要做的是,实现一个
Pipeline,将ResultItem转换为需要被持久化的实例对象。
- 需要做的是,实现一个
注解模式
注解模式下,WebMagic 内置了一个
PageModelPipeline。
可以很优雅地定义一个
JobInfoDaoPipeline来实现这个功能。
基本 Pipeline 模式
如果我们使用原始的
Pipeline接口,要怎么完成呢?其实答案也很简单,如果你要保存一个对象,那么就需要在抽取的时候,将它保存为一个对象。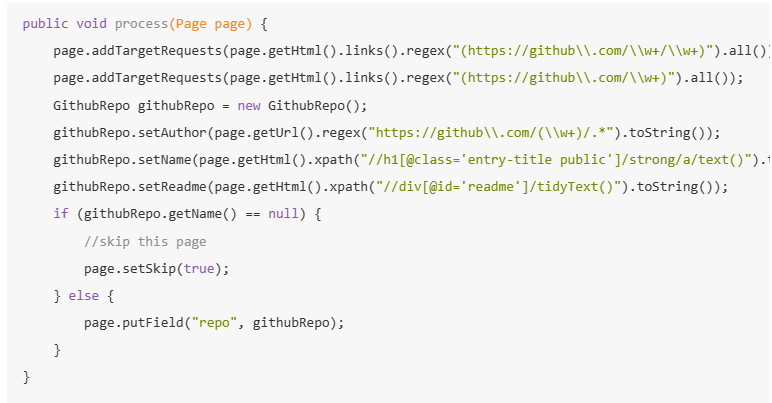
在
Pipeline中,只要使用:
就可以获取这个对象了。
WebMagic 已经提供的几个 Pipeline
使用和定制 Scheduler
Scheduler是对 WebMagic 中进行 URL 管理的组件。一般来说,Scheduler包括两个作用:- 对待抓取的 URL 队列进行管理。
- 对已抓取的 URL 进行去重。
WebMagic 内置了几个常用的
Scheduler。如果你只是在本地执行规模比较小的爬虫,那么基本无需定制Scheduler,但是了解一下已经提供的几个Scheduler还是有意义的。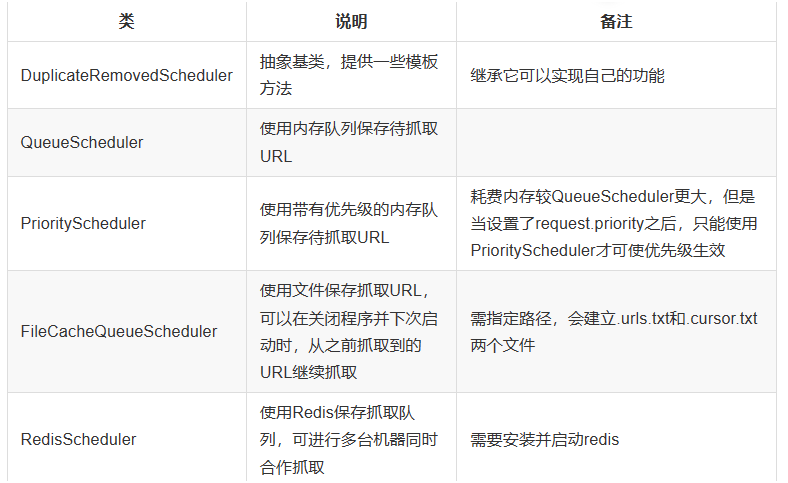
在 0.5.1 版本里面,
Scheduler的去重部分被单独抽象成了一个接口:DuplicateRemover,从而可以为统一个Scheduler选择不同的去重方式,以适应不同的需要,目前提供了两种去重方式。
所有默认的
Scheduler都使用HashSetDuplicateRemover来进行去重,(除开RedisScheduler是使用 Redis 的 set 进行去重)。如果你的 URL 较多,使用HashSetDuplicateRemover会比较占用内存,所以也可以尝试使用BloomFilterDuplicateRemover: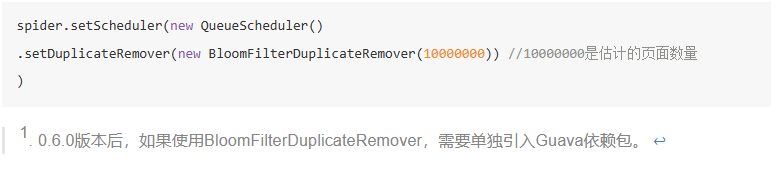
使用和定制 Downloader
WebMagic 的默认 Downloader 基于 HttpClient。一般来说,你无须自己实现 Downloader,不过 HttpClientDownloader 也预留了几个扩展点,以满足不同场景的需求。
另外,你可能希望通过其他方式来实现页面下载,例如使用 SeleniumDownloader 来渲染动态页面。
CSS选择器
在CSS中,选择器是选取需设置样式的元素的模式。
| 选择器 | 例子 | 例子描述 |
|---|---|---|
| .class | .intro | 选择 class="intro" 的所有元素。 |
| .class1.class2 | .name1.name2 | 选择 class 属性中同时有 name1 和 name2 的所有元素。 |
| .class1 .class2 | .name1 .name2 | 选择作为类名 name1 元素后代的所有类名 name2 元素。 |
| #id | #firstname | 选择 id="firstname" 的元素。 |
| * | * | 选择所有元素。 |
| element | p | 选择所有 <p> 元素。 |
| element.class | p.intro | 选择 class="intro" 的所有 <p> 元素。 |
| element,element | div, p | 选择所有 <div> 元素和所有 <p> 元素。 |
| element element | div p | 选择 <div> 元素内的所有 <p> 元素。 |
| element>element | div > p | 选择父元素是 <div> 的所有 <p> 元素。 |
| element+element | div + p | 选择紧跟 <div> 元素的首个 <p> 元素。 |
| element1~element2 | p ~ ul | 选择前面有 <p> 元素的每个 <ul> 元素。 |
| [attribute] | [target] | 选择带有 target 属性的所有元素。 |
| [attribute=value] | [target=_blank] | 选择带有 target="_blank" 属性的所有元素。 |
| [attribute~=value] | [title~=flower] | 选择 title 属性包含单词 “flower” 的所有元素。 |
| [attribute|=value] | [lang|=en] | 选择 lang 属性值以 “en” 开头的所有元素。 |
| [attribute^=value] | a[href^=”https”] | 选择其 href 属性值以 “https” 开头的每个 <a> 元素。 |
| [attribute$=value] | a[href$=”.pdf”] | 选择其 href 属性以 “.pdf” 结尾的所有 <a> 元素。 |
| [attribute*=value] | a[href*=”w3school”] | 选择其 href 属性值中包含 “w3school” 子串的每个 <a> 元素。 |
| :active | a:active | 选择活动链接。 |
| ::after | p::after | 在每个 <p> 的内容之后插入内容。 |
| ::before | p::before | 在每个 <p> 的内容之前插入内容。 |
| :checked | input:checked | 选择每个被选中的 <input> 元素。 |
| :default | input:default | 选择默认的 <input> 元素。 |
| :disabled | input:disabled | 选择每个被禁用的 <input> 元素。 |
| :empty | p:empty | 选择没有子元素的每个 <p> 元素(包括文本节点)。 |
| :enabled | input:enabled | 选择每个启用的 <input> 元素。 |
| :first-child | p:first-child | 选择属于父元素的第一个子元素的每个 <p> 元素。 |
| ::first-letter | p::first-letter | 选择每个 <p> 元素的首字母。 |
| ::first-line | p::first-line | 选择每个 <p> 元素的首行。 |
| :first-of-type | p:first-of-type | 选择属于其父元素的首个 <p> 元素的每个 <p> 元素。 |
| :focus | input:focus | 选择获得焦点的 <input> 元素。 |
| :fullscreen | :fullscreen | 选择处于全屏模式的元素。 |
| :hover | a:hover | 选择鼠标指针位于其上的链接。 |
| :in-range | input:in-range | 选择其值在指定范围内的 <input> 元素。 |
| :indeterminate | input:indeterminate | 选择处于不确定状态的 <input> 元素。 |
| :invalid | input:invalid | 选择具有无效值的所有 <input> 元素。 |
| :lang(language) | p:lang(it) | 选择 lang 属性等于 “it”(意大利)的每个 <p> 元素。 |
| :last-child | p:last-child | 选择属于其父元素最后一个子元素每个 <p> 元素。 |
| :last-of-type | p:last-of-type | 选择属于其父元素的最后 <p> 元素的每个 <p> 元素。 |
| :link | a:link | 选择所有未访问过的链接。 |
| :not(selector) | :not(p) | 选择非 <p> 元素的每个元素。 |
| :nth-child(n) | p:nth-child(2) | 选择属于其父元素的第二个子元素的每个 <p> 元素。 |
| :nth-last-child(n) | p:nth-last-child(2) | 同上,从最后一个子元素开始计数。 |
| :nth-of-type(n) | p:nth-of-type(2) | 选择属于其父元素第二个 <p> 元素的每个 <p> 元素。 |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | 同上,但是从最后一个子元素开始计数。 |
| :only-of-type | p:only-of-type | 选择属于其父元素唯一的 <p> 元素的每个 <p> 元素。 |
| :only-child | p:only-child | 选择属于其父元素的唯一子元素的每个 <p> 元素。 |
| :optional | input:optional | 选择不带 required 属性的 <input> 元素。 |
| :out-of-range | input:out-of-range | 选择值超出指定范围的 <input> 元素。 |
| ::placeholder | input::placeholder | 选择已规定 placeholder 属性的 <input> 元素。 |
| :read-only | input:read-only | 选择已规定 readonly 属性的 <input> 元素。 |
| :read-write | input:read-write | 选择未规定 readonly 属性的 <input> 元素。 |
| :required | input:required | 选择已规定 required 属性的 <input> 元素。 |
| :root | :root | 选择文档的根元素。 |
| ::selection | ::selection | 选择用户已选取的元素部分。 |
| :target | #news:target | 选择当前活动的 #news 元素。 |
| :valid | input:valid | 选择带有有效值的所有 <input> 元素。 |
| :visited | a:visited | 选择所有已访问的链接。 |
Xpath
- Xpath 是一门在 XML 文档中查找信息的语言。Xpath 可用来在 XML 文档中对元素和属性进行遍历。
什么是 XPath?
- XPath 使用路径表达式在 XML 文档中进行导航。
- XPath 包含一个标准函数库。
- XPath 是 XSLT 中的主要元素。
- XPath 是一个 W3C 标准。
XPath 路径表达式
- XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
XPath 标准函数
- XPath 含有超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等。
XPath 节点
- 在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。
|
<bookstore>(文档节点)<author>J K. Rowling</author>(元素节点)lang="en"(属性节点)
XPath 术语
节点(Node)
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。基本值(或称原子值,Atomic value)
基本值是无父或无子的节点。- 基本值的例子:
- J K. Rowling
- “en”
- 基本值的例子:
项目(Item)
项目是基本值或者节点。节点关系
父(Parent)
每个元素以及属性都有一个父。在下面的例子中,book元素是title、author、year以及price元素的父:<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>子(Children)
元素节点可有零个、一个或多个子。在下面的例子中,title、author、year以及price元素都是book元素的子:<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>同胞(Sibling)
拥有相同的父的节点。在下面的例子中,title、author、year以及price元素都是同胞:<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>先辈(Ancestor)
某节点的父、父的父,等等。在下面的例子中,title元素的先辈是book元素和bookstore元素:<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>后代(Descendant)
某个节点的子,子的子,等等。
XPath 语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
最有用的路径表达式:
表达式 描述 nodename 选取此节点的所有子节点。 / 从根节点选取。 // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 . 选取当前节点。 .. 选取当前节点的父节点。 @ 选取属性。 实例
路径表达式 结果 bookstore 选取 bookstore元素的所有子节点。/bookstore 选取根元素 bookstore。注释:假如路径起始于正斜杠/,则此路径始终代表到某元素的绝对路径!bookstore/book 选取属于 bookstore的子元素的所有book元素。//book 选取所有 book子元素,而不管它们在文档中的位置。bookstore//book 选择属于 bookstore元素的后代的所有book元素,而不管它们位于bookstore之下的什么位置。//@lang 选取名为 lang的所有属性。谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
实例
路径表达式 结果 /bookstore/book[1] 选取属于 bookstore子元素的第一个book元素。/bookstore/book[last()] 选取属于 bookstore子元素的最后一个book元素。/bookstore/book[last()-1] 选取属于 bookstore子元素的倒数第二个book元素。/bookstore/book[position()<3] 选取最前面的两个属于 bookstore元素的子元素的book元素。//title[@lang] 选取所有拥有名为 lang的属性的title元素。//title[@lang=’eng’] 选取所有 title元素,且这些元素拥有值为 eng 的lang属性。/bookstore/book[price>35.00] 选取 bookstore元素的所有book元素,且其中的price元素的值须大于 35.00。/bookstore/book[price>35.00]/title 选取 bookstore元素中的book元素的所有title元素,且其中的price元素的值须大于 35.00。选取未知节点
通配符 描述 * 匹配任何元素节点。 @* 匹配任何属性节点。 node() 匹配任何类型的节点。 实例
路径表达式 结果 /bookstore/* 选取 bookstore元素的所有子元素。//* 选取文档中的所有元素。 //title[@*] 选取所有带有属性的 title元素。选取若干路径
通过在路径表达式中使用 “|” 运算符,您可以选取若干个路径。
实例
路径表达式 结果 //book/title | //book/price 选取 book元素的所有title和price元素。//title | //price 选取文档中的所有 title和price元素。/bookstore/book/title | //price 选取属于 bookstore元素的book元素的所有title元素,以及文档中所有的price元素。XPath Axes(轴)
轴可定义相对于当前节点的节点集。
轴名称 结果 ancestor 选取当前节点的所有先辈(父、祖父等)。 ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 attribute 选取当前节点的所有属性。 child 选取当前节点的所有子元素。 descendant 选取当前节点的所有后代元素(子、孙等)。 descendant-or-self 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 following 选取文档中当前节点的结束标签之后的所有节点。 namespace 选取当前节点的所有命名空间节点。 parent 选取当前节点的父节点。 preceding 选取文档中当前节点的开始标签之前的所有节点。 preceding-sibling 选取当前节点之前的所有同级节点。 self 选取当前节点。 位置路径表达式
位置路径可以是绝对的,也可以是相对的。绝对路径起始于正斜杠
/,而相对路径不会这样。在两种情况中,位置路径均包括一个或多个步,每个步均被斜杠分割:绝对位置路径:
/step/step/...
相对位置路径:
step/step/...
步(step)包括:
- 轴(axis):定义所选节点与当前节点之间的树关系。
- 节点测试(node-test):识别某个轴内部的节点。
- 零个或者更多谓语(predicate):更深入地提炼所选的节点集。
步的语法:
轴名称::节点测试[谓语]
实例
例子 结果 child::book 选取所有属于当前节点的子元素的 book节点。attribute::lang 选取当前节点的 lang属性。child::* 选取当前节点的所有子元素。 attribute::* 选取当前节点的所有属性。 child::text() 选取当前节点的所有文本子节点。 child::node() 选取当前节点的所有子节点。 descendant::book 选取当前节点的所有 book后代。ancestor::book 选择当前节点的所有 book先辈。ancestor-or-self::book 选取当前节点的所有 book先辈以及当前节点(如果此节点是book节点)。child::*/child::price 选取当前节点的所有 price孙节点。XPath 运算符
XPath 表达式可返回节点集、字符串、逻辑值以及数字。
运算符 描述 实例 返回值 | 计算两个节点集 //book | //cd 返回所有拥有 book和cd元素的节点集。+ 加法 6 + 4 10 - 减法 6 - 4 2 * 乘法 6 * 4 24 div 除法 8 div 4 2 = 等于 price=9.80 如果 price是 9.80,则返回 true。如果 price 是 9.90,则返回 false。!= 不等于 price!=9.80 如果 price是 9.90,则返回 true。如果 price 是 9.80,则返回 false。< 小于 price<9.80 如果 price是 9.00,则返回 true。如果 price 是 9.90,则返回 false。<= 小于或等于 price<=9.80 如果 price是 9.00,则返回 true。如果 price 是 9.90,则返回 false。> 大于 price>9.80 如果 price是 9.90,则返回 true。如果 price 是 9.80,则返回 false。>= 大于或等于 price>=9.80 如果 price是 9.90,则返回 true。如果 price 是 9.70,则返回 false。or 或 price=9.80 or price=9.70 如果 price是 9.80,则返回 true。如果 price 是 9.50,则返回 false。and 与 price>9.00 and price<9.90 如果 price是 9.80,则返回 true。如果 price 是 8.50,则返回 false。mod 计算除法的余数 5 mod 2 1
XML
- XML 指可扩展标记语言
- XML 被设计用来传输和存储数据
什么是 XML?
- XML 指可扩展标记语言(EXtensible Markup Language)。
- XML 是一种标记语言,很类似 HTML。
- XML 的设计宗旨是传输数据,而非显示数据。
- XML 标签没有被预定义。您需要自行定义标签。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准。
XML 与 HTML 的主要差异
- XML 被设计为传输和存储数据,其焦点是数据的内容。
- HTML 被设计用来显示数据,其焦点是数据的外观。
- HTML 旨在显示信息,而 XML 旨在传输信息。
XML 是不作为的
- XML 仅仅是纯文本。
它仅仅是纯文本而已。有能力处理纯文本的软件都可以处理 XML。不过,能够读懂 XML 的应用程序可以有针对性地处理 XML 的标签。标签的功能性意义依赖于应用程序的特性。
XML 树结构
|
第一行是 XML 声明。它定义 XML 的版本 (1.0) 和所使用的编码 (ISO-8859-1 = Latin-1/西欧字符集)。
下一行描述文档的根元素(像在说:“本文档是一个便签”)。
接下来 4 行描述根的 4 个子元素(to, from, heading 以及 body):
<to>George</to><from>John</from><heading>Reminder</heading><body>Don't forget the meeting!</body>
最后一行定义根元素的结尾:
</note>
XML 文档形成一种树结构
- XML 文档必须包含根元素。该元素是所有其他元素的父元素。
- XML 文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端。所有元素均可拥有子元素:
<root> |
- 父、子以及同胞等术语用于描述元素之间的关系。父元素拥有子元素。相同层级上的子元素成为同胞(兄弟或姐妹)。所有元素均可拥有文本内容和属性(类似 HTML 中)。
<bookstore> |
- 例子中的根元素是
<bookstore>。文档中的所有<book>元素都被包含在<bookstore>中。 <book>元素有 4 个子元素:<title>、<author>、<year>、<price>。
XML 语法规则
- 所有 XML 元素都须有关闭标签
XML 声明没有关闭标签。这不是错误。声明不属于 XML 本身的组成部分。它不是 XML 元素,也不需要关闭标签。 - XML 标签对大小写敏感
XML 标签对大小写敏感。在 XML 中,标签<Letter>与标签<letter>是不同的。必须使用相同的大小写来编写打开标签和关闭标签:
<Message>这是错误的。</message> |
- XML 必须正确地嵌套
正确嵌套的意思是:由于<i>元素是在<b>元素内打开的,那么它必须在<b>元素内关闭。
<b><i>This text is bold and italic</i></b> |
- XML 文档必须有根元素
XML 文档必须有一个元素是所有其他元素的父元素。该元素称为根元素。
<root> |
- XML 的属性值须加引号
与 HTML 类似,XML 也可拥有属性(名称/值的对)。在 XML 中,XML 的属性值须加引号。请研究下面的两个 XML 文档。第一个是错误的,第二个是正确的:
<note date=08/08/2008> |
- 在第一个文档中的错误是,
note元素中的date属性没有加引号。
实体引用
在 XML 中,一些字符拥有特殊的意义。如果你把字符 < 放在 XML 元素中,会发生错误,这是因为解析器会把它当作新元素的开始。为了避免这个错误,请用实体引用来代替 < 字符:
<message>if salary <1000 then</message> |
在 XML 中,有 5 个预定义的实体引用:
| 符号 | 实体引用 | 描述 |
|---|---|---|
< |
< |
小于 |
> |
> |
大于 |
& |
& |
和号 |
' |
' |
单引号 |
" |
" |
引号 |
在 XML 中,只有字符 < 和 & 确实是非法的。大于号是合法的,但是用实体引用来代替它是一个好习惯。
XML 中的注释
在 XML 中编写注释的语法与 HTML 的语法很相似:
<!-- This is a comment --> |
在 XML 中,空格会被保留
HTML 会把多个连续的空格字符裁减(合并)为一个:
HTML: Hello my name is David. |
在 XML 中,文档中的空格不会被删节。
XML 以 LF 存储换行
在 Windows 应用程序中,换行通常以一对字符来存储:回车符 (CR) 和换行符 (LF)。在 Unix 应用程序中,新行以 LF 字符存储。而 Macintosh 应用程序使用 CR 来存储新行。
什么是 XML 元素?
XML 元素指的是从(且包括)开始标签直到(且包括)结束标签的部分。元素可包含其他元素、文本或者两者的混合物。元素也可以拥有属性。
<bookstore> |
- 在上例中,
<bookstore>和<book>都拥有元素内容,因为它们包含了其他元素。<author>只有文本内容,因为它仅包含文本。 - 在上例中,只有
<book>元素拥有属性 (category="CHILDREN")。
XML 命名规则
XML 元素必须遵循以下命名规则:
- 名称可以含字母、数字以及其他的字符。
- 名称不能以数字或者标点符号开始。
- 名称不能以字符 “xml”(或者 XML、Xml)开始。
- 名称不能包含空格。
- 可使用任何名称,没有保留的字词。
最佳命名习惯
- 名称应当比较简短,比如:
<book_title>,而不是:<the_title_of_the_book>。 - 避免 “-“ 字符。如果您按照这样的方式进行命名:”first-name”,一些软件会认为你需要提取第一个单词。
- 避免 “.” 字符。如果您按照这样的方式进行命名:”first.name”,一些软件会认为 “name” 是对象 “first” 的属性。
- 避免 “:” 字符。冒号会被转换为命名空间来使用。
XML 元素是可扩展的
XML 元素是可扩展,以携带更多的信息。XML 的优势之一,就是可以经常在不中断应用程序的情况进行扩展。
XML 属性
XML 元素可以在开始标签中包含属性,类似 HTML。属性 (Attribute) 提供关于元素的额外(附加)信息。属性通常提供不属于数据组成部分的信息。
在下面的例子中,文件类型与数据无关,但是对需要处理这个元素的软件来说却很重要:
<file type="gif">computer.gif</file> |
XML 属性必须加引号
属性值必须被引号包围,不过单引号和双引号均可使用。比如一个人的性别,person 标签可以这样写:
<person sex="female"> |
或者这样也可以:
<person sex='female'> |
如果属性值本身包含双引号,那么有必要使用单引号包围它:
<gangster name='George "Shotgun" Ziegler'> |
或者可以使用实体引用:
<gangster name="George "Shotgun" Ziegler"> |
XML 元素 vs. 属性
<person sex="female"> |
在第一个例子中,sex 是一个属性。在第二个例子中,sex 则是一个子元素。两个例子均可提供相同的信息。没有什么规矩可以告诉我们什么时候该使用属性,而什么时候该使用子元素。在 HTML 中,属性用起来很便利,但是在 XML 中,您应该尽量避免使用属性。如果信息感觉起来很像数据,那么请使用子元素吧。
避免 XML 属性?
因使用属性而引起的一些问题:
- 属性无法包含多重的值(元素可以)。
- 属性无法描述树结构(元素可以)。
- 属性不易扩展(为未来的变化)。
- 属性难以阅读和维护。
元数据(有关数据的数据)应当存储为属性,而数据本身应当存储为元素。
XML 验证
拥有正确语法的 XML 被称为 “形式良好” 的 XML。
通过 DTD 验证的 XML 是 “合法” 的 XML。
“形式良好”(Well Formed)的 XML 文档会遵守前几章介绍过的 XML 语法规则:
- XML 文档必须有根元素。
- XML 文档必须有关闭标签。
- XML 标签对大小写敏感。
- XML 元素必须被正确的嵌套。
- XML 属性必须加引号。
合法的 XML 文档是 “形式良好” 的 XML 文档,同样遵守文档类型定义 (DTD) 的语法规则:
|
在上例中,DOCTYPE 声明是对外部 DTD 文件的引用。下面的段落展示了这个文件的内容。
XML DTD
DTD 的作用是定义 XML 文档的结构。它使用一系列合法的元素来定义文档结构: