
Netty入门
Netty基础
Netty 是什么?
- Netty 是一个异步的、基于事件驱动的网络应用框架,用于快速开发可维护、高性能的网络服务器和客户端。
一开始需要树立正确的观念:
- 把
channel理解为数据的通道。 - 把
msg理解为流动的数据,最开始输入是ByteBuf,但经过pipeline的加工,会变成其它类型对象,最后输出又变成ByteBuf。 - 把
handler理解为数据的处理工序:- 工序有多道,合在一起就是
pipeline,pipeline负责发布事件(读、读取完成…)传播给每个handler,handler对自己感兴趣的事件进行处理(重写了相应事件处理方法)。 handler分Inbound和Outbound两类。
- 工序有多道,合在一起就是
- 把
eventLoop理解为处理数据的工人:- 工人可以管理多个
channel的 IO 操作,并且一旦工人负责了某个channel,就要负责到底(绑定)。 - 工人既可以执行 IO 操作,也可以进行任务处理,每位工人有任务队列,队列里可以堆放多个
channel的待处理任务,任务分为普通任务、定时任务。 - 工人按照
pipeline顺序,依次按照handler的规划(代码)处理数据,可以为每道工序指定不同的工人。
- 工人可以管理多个
组件
EventLoop(事件循环对象)
- 事件循环对象,
EventLoop本质是一个单线程执行器(同时维护了一个 Selector),里面有run方法处理Channel上源源不断的 IO 事件。 - 它的继承关系比较复杂:
- 一条线是继承自
java.util.concurrent.ScheduledExecutorService,因此包含了线程池中所有的方法。 - 另一条线是继承自 Netty 自己的
OrderedEventExecutor:- 提供了
boolean inEventLoop(Thread thread)方法判断一个线程是否属于此EventLoop。 - 提供了
parent方法来看看自己属于哪个EventLoopGroup。
- 提供了
- 一条线是继承自
EventLoopGroup(事件循环组)
EventLoopGroup是一组EventLoop,Channel一般会调用EventLoopGroup的register方法来绑定其中一个EventLoop,后续这个Channel上的 IO 事件都由此EventLoop来处理(保证了 IO 事件处理时的线程安全)。- 继承自 Netty 自己的
EventExecutorGroup:- 实现了
Iterable接口,提供遍历EventLoop的能力。 - 另有
next方法获取集合中下一个EventLoop。
- 实现了
优雅关闭
- 优雅关闭
shutdownGracefully方法。该方法会首先切换EventLoopGroup到关闭状态,从而拒绝新的任务的加入,然后在任务队列的任务都处理完成后,停止线程的运行,从而确保整体应用是在正常有序的状态下退出的。
可以看到两个工人轮流处理 channel,但工人与 channel 之间进行了绑定。
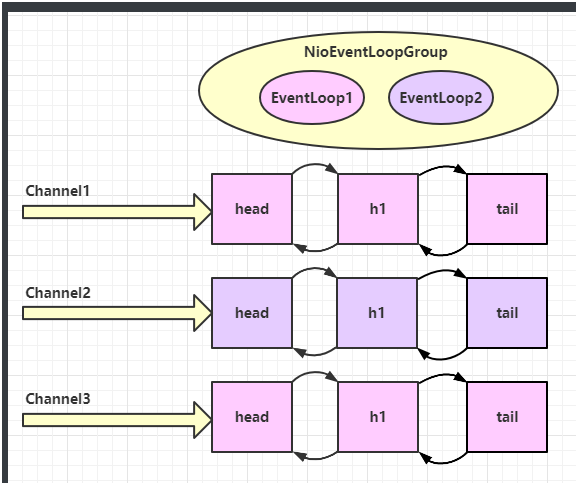
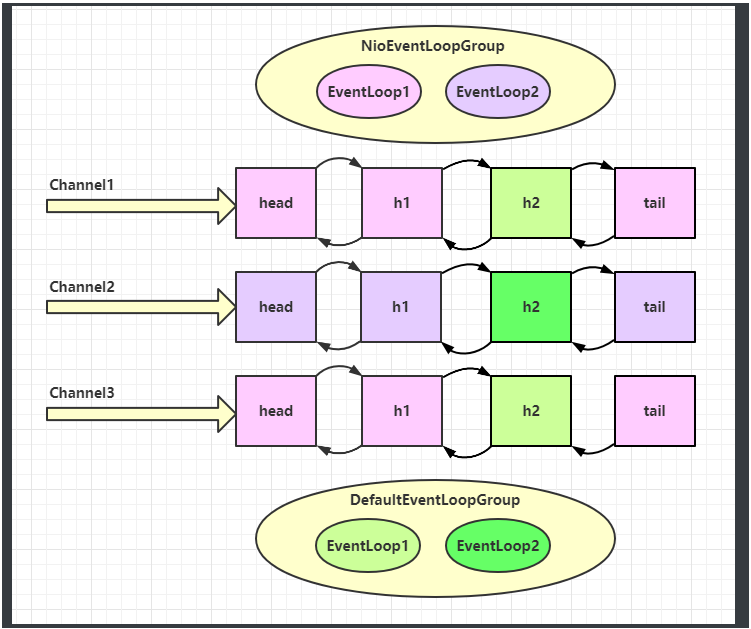
再增加两个非 NIO 工人:
NIO 工人和非 NIO 工人也分别绑定了 channel(LoggingHandler 由 NIO 工人执行,而我们自己的 handler 由非 NIO 工人执行)。
Handler 执行中如何换人?
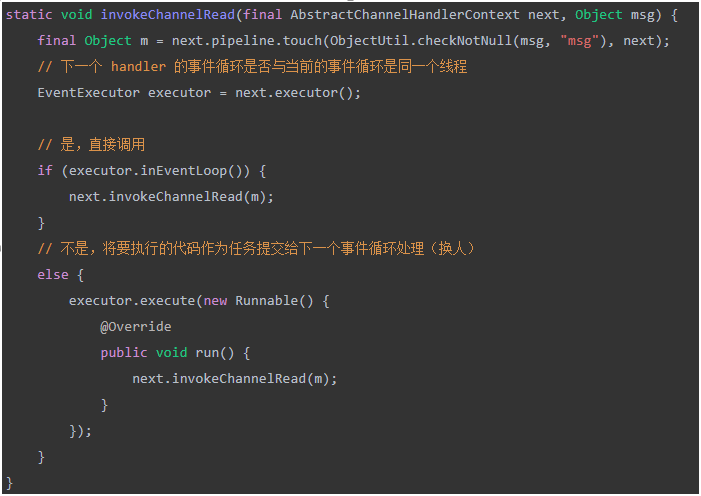
- 如果两个
handler绑定的是同一个线程,那么就直接调用。 - 否则,把要调用的代码封装为一个任务对象,由下一个
handler的线程来调用。
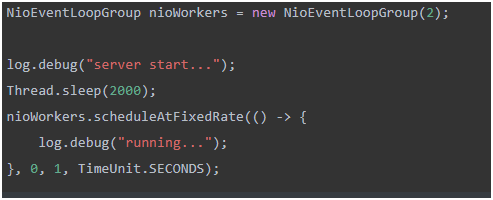
NioEventLoop 可以处理普通任务,也可以处理定时任务
NioEventLoop除了可以处理 IO 事件,同样可以向它提交普通任务和定时任务。
Channel
channel的主要作用:close()可以用来关闭channel。closeFuture()用来处理channel的关闭:sync方法作用是同步等待channel关闭。addListener方法是异步等待channel关闭。
pipeline()方法添加处理器。write()方法将数据写入。writeAndFlush()方法将数据写入并刷出。
- 异步提升的是什么?
- 单线程没法异步提高效率,必须配合多线程、多核 CPU 才能发挥异步的优势。
- 异步并没有缩短响应时间,反而有所增加。
- 合理进行任务拆分,也是利用异步的关键。
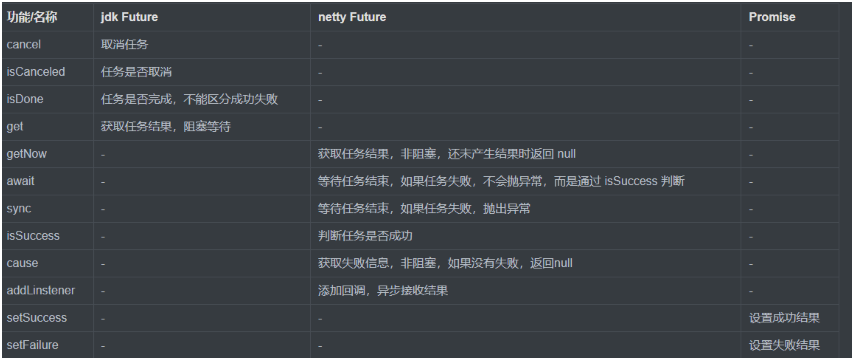
Future & Promise
- Netty 中的
Future与 JDK 中的Future同名,但是是两个接口,Netty 的Future继承自 JDK 的Future,而Promise又对 NettyFuture进行了扩展:- JDK
Future只能同步等待任务结束(或成功、或失败)才能得到结果。 - Netty
Future可以同步等待任务结束得到结果,也可以异步方式得到结果,但都是要等任务结束。 - Netty
Promise不仅有 NettyFuture的功能,而且脱离了任务独立存在,只作为两个线程间传递结果的容器。
- JDK
Handler & Pipeline
ChannelHandler用来处理Channel上的各种事件,分为入站、出站两种。所有ChannelHandler被连成一串,就是Pipeline。- 入站处理器通常是
ChannelInboundHandlerAdapter的子类,主要用来读取客户端数据,写回结果。 - 出站处理器通常是
ChannelOutboundHandlerAdapter的子类,主要对写回结果进行加工。
- 入站处理器通常是
- 每个
Channel是一个产品的加工车间,Pipeline是车间中的流水线,ChannelHandler就是流水线上的各道工序,而后面要讲的ByteBuf是原材料,经过很多工序的加工:先经过一道道入站工序,再经过一道道出站工序最终变成产品。 ChannelInboundHandlerAdapter是按照addLast的顺序执行的,而ChannelOutboundHandlerAdapter是按照addLast的逆序执行的。ChannelPipeline的实现是一个ChannelHandlerContext(包装了ChannelHandler)组成的双向链表。
- 入站处理器中,
ctx.fireChannelRead(msg)是 调用下一个入站处理器。 ctx.channel().write(msg)会 从尾部开始触发后续出站处理器的执行。- 出站处理器中,
ctx.write(msg, promise)的调用也会 触发上一个出站处理器。
ctx.channel().write(msg) vs ctx.write(msg)
- 都是触发出站处理器的执行。
ctx.channel().write(msg)从尾部开始查找出站处理器。ctx.write(msg)是从当前节点找上一个出站处理器。
ByteBuf
- 是对字节数据的封装。
- 直接内存 vs 堆内存:
- 可以使用下面的代码来创建池化基于堆的
ByteBuf: - 可以使用下面的代码来创建池化基于直接内存的
ByteBuf:
- 可以使用下面的代码来创建池化基于堆的
- 直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用。
- 直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放。
- 池化 vs 非池化:
- 池化的最大意义在于可以重用
ByteBuf,优点有:- 没有池化,则每次都得创建新的
ByteBuf实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力。 - 有了池化,则可以重用池中
ByteBuf实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率。 - 高并发时,池化功能更节约内存,减少内存溢出的可能。
- 没有池化,则每次都得创建新的
- 池化功能是否开启,可以通过下面的系统环境变量来设置:
- 4.1 以后,非 Android 平台默认启用池化实现,Android 平台启用非池化实现。
- 4.1 之前,池化功能还不成熟,默认是非池化实现。
- 池化的最大意义在于可以重用



组成
ByteBuf由四部分组成: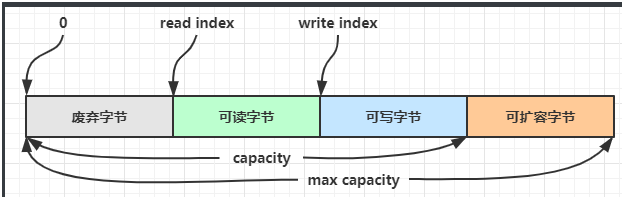
- 最开始读写指针都在 0 位置。
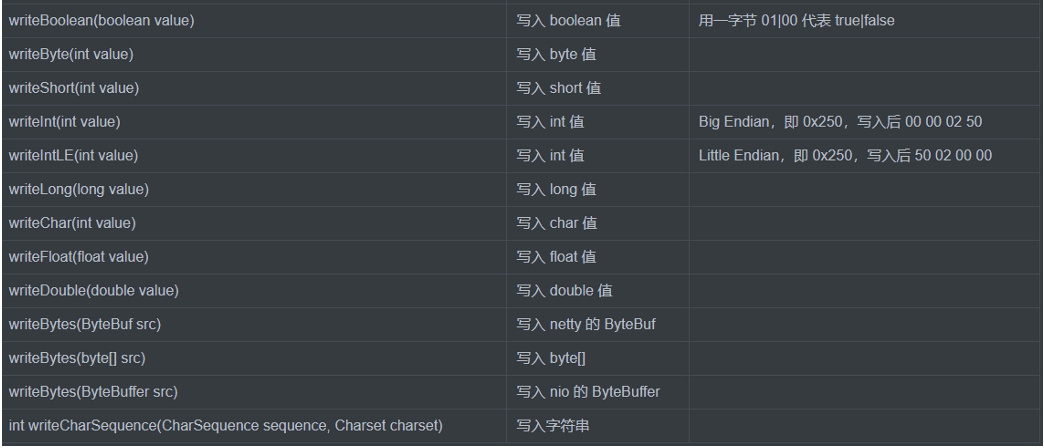
写入
扩容
- 再写入一个
int整数时,容量不够了(初始容量是 10),这时会引发扩容。 - 扩容规则是:
- 如果写入后数据大小未超过 512,则选择下一个 16 的整数倍,例如写入后大小为 12 ,则扩容后
capacity是 16。 - 如果写入后数据大小超过 512,则选择下一个 2^n,例如写入后大小为 513,则扩容后
capacity是 2^10=1024(2^9=512 已经不够了)。 - 扩容不能超过
max capacity会报错。
- 如果写入后数据大小未超过 512,则选择下一个 16 的整数倍,例如写入后大小为 12 ,则扩容后
读取
- 读过的内容,就属于废弃部分了,再读只能读那些尚未读取的部分。
- 如果需要重复读取,可以在
read前先做个标记mark,这时要重复读取的话,重置到标记位置reset。
retain & release
- 由于 Netty 中有堆外内存的
ByteBuf实现,堆外内存最好是手动来释放,而不是等 GC 垃圾回收。UnpooledHeapByteBuf使用的是 JVM 内存,只需等 GC 回收内存即可。UnpooledDirectByteBuf使用的就是直接内存了,需要特殊的方法来回收内存。PooledByteBuf和它的子类使用了池化机制,需要更复杂的规则来回收内存。- Netty 这里采用了引用计数法来控制回收内存,每个
ByteBuf都实现了ReferenceCounted接口:- 每个
ByteBuf对象的初始计数为 1。 - 调用
release方法计数减 1,如果计数为 0,ByteBuf内存被回收。 - 调用
retain方法计数加 1,表示调用者没用完之前,其它handler即使调用了release也不会造成回收。 - 当计数为 0 时,底层内存会被回收,这时即使
ByteBuf对象还在,其各个方法均无法正常使用。
- 每个
谁来负责 release 呢?
- 基本规则是,谁是最后使用者,谁负责 release。
- 入站
ByteBuf处理原则:- 对原始
ByteBuf不做处理,调用ctx.fireChannelRead(msg)向后传递,这时无须release。 - 将原始
ByteBuf转换为其它类型的 Java 对象,这时ByteBuf就没用了,必须release。 - 如果不调用
ctx.fireChannelRead(msg)向后传递,那么也必须release。 - 注意各种异常,如果
ByteBuf没有成功传递到下一个ChannelHandler,必须release。 - 假设消息一直向后传,那么
TailContext会负责释放未处理消息(原始的ByteBuf)。
- 对原始
- 出站
ByteBuf处理原则:- 出站消息最终都会转为
ByteBuf输出,一直向前传,由HeadContextflush后release。
- 出站消息最终都会转为
异常处理原则
- 有时候不清楚
ByteBuf被引用了多少次,但又必须彻底释放,可以循环调用release直到返回true。
Slice
- 【零拷贝】的体现之一,对原始
ByteBuf进行切片成多个ByteBuf,切片后的ByteBuf并没有发生内存复制,还是使用原始ByteBuf的内存,切片后的ByteBuf维护独立的read,write指针。 - 无参
slice是从原始ByteBuf的read index到write index之间的内容进行切片,切片后的max capacity被固定为这个区间的大小,因此不能追加write。 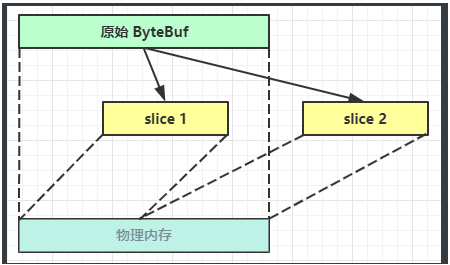
Duplicate
- 【零拷贝】的体现之一,就好比截取了原始
ByteBuf所有内容,并且没有max capacity的限制,也是与原始ByteBuf使用同一块底层内存,只是读写指针是独立的。 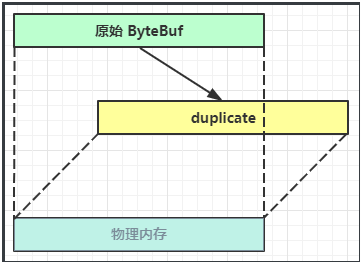
Copy
- 会将底层内存数据进行深拷贝,因此无论读写,都与原始
ByteBuf无关。
CompositeByteBuf
- 【零拷贝】的体现之一,可以将多个
ByteBuf合并为一个逻辑上的ByteBuf,避免拷贝。 CompositeByteBuf是一个组合的ByteBuf,它内部维护了一个Component数组,每个Component管理一个ByteBuf,记录了这个ByteBuf相对于整体偏移量等信息,代表着整体中某一段的数据:- 优点:对外是一个虚拟视图,组合这些
ByteBuf不会产生内存复制。 - 缺点:复杂了很多,多次操作会带来性能的损耗。
- 优点:对外是一个虚拟视图,组合这些
Unpooled
Unpooled是一个工具类,类如其名,提供了非池化的ByteBuf创建、组合、复制等操作。
ByteBuf 优势
- 池化 - 可以重用池中
ByteBuf实例,更节约内存,减少内存溢出的可能。 - 读写指针分离,不需要像
ByteBuffer一样切换读写模式。 - 可以自动扩容。
- 支持链式调用,使用更流畅。
- 很多地方体现零拷贝,例如
slice、duplicate、CompositeByteBuf。
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Related Articles

Comment